In Defense of 'Circling p-values'
You noticed that the p-values in a paper are close to .05. Does this make you a bad person? Can ‘circling p-values’ ever be a useful heuristic? My two cents on an (apparently?) controversial topic.

Today I F-ed Up: Two Errors I Recently Made In an Almost-Published Paper
Let’s talk about errors in research, using myself as an example.
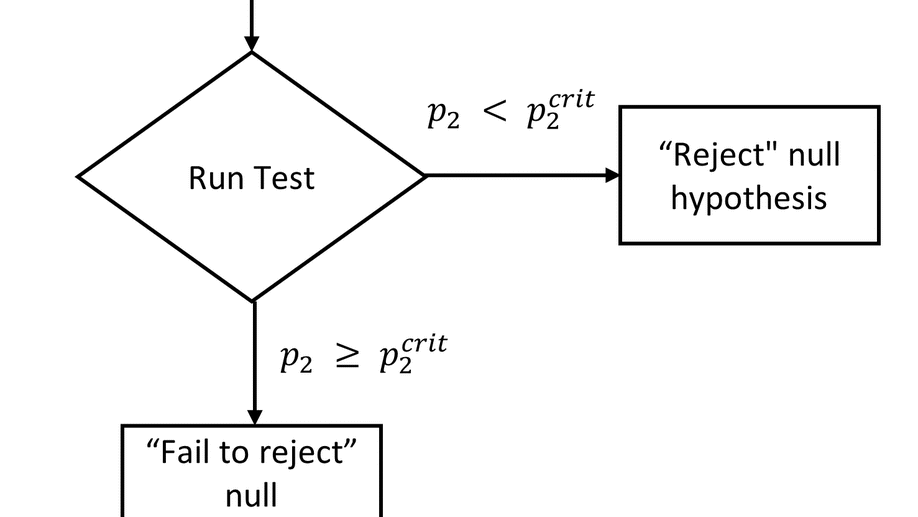
Designing More Efficient Studies with Group Sequential Designs
Creating studies that are powered to detect the smallest effect of interest… without collecting more data than you need to detect bigger effects
Four Lessons from Reproducing JCR Studies
What happens when two researchers attempt to reproduce all the pre-registered studies with open data published in JCR?
Can You Learn What Helps a Baby Sleep at Night?
How natural improvements in outcomes can lead us to form strong, yet incorrect, beliefs about how the world works.
Increasing the Informativeness of Power Analysis
If power analysis cannot be based on the expected effect size, what should it be based on?
Power Analysis in Consumer Research: A Fool’s Errand?
Why power analysis, as traditionally performed, isn’t a good tool for choosing sample size.
Large P-Values Cannot be Explained by Power Analysis
Can p-values be close to .05 because researchers ran careful power analysis, and collected ‘just enough’ participants to detect their effect? In this blog post, I evaluate the merits of this argument.